Designing a scalable supplier onboarding system for enterprise TPRM, transforming a manual process into a high-volume, data-controlled workflow.
Supplier onboarding is the entry point to all TPRM workflows — compliance, audits, and risk monitoring. Yet the experience was designed as a linear, single-entry flow: one supplier, one form, 15+ fields, manually completed every time.
At ~3 minutes per supplier, enterprise teams managing 50–500 vendors were spending entire workdays on repetitive data entry. As volume increased, the system failed to support real workflows — teams began bypassing the product entirely, relying on offline spreadsheets and backend workarounds to complete onboarding.
The result: the product's core entry point was no longer usable at scale, creating operational bottlenecks, fragmented workflows, and reduced trust in downstream data.
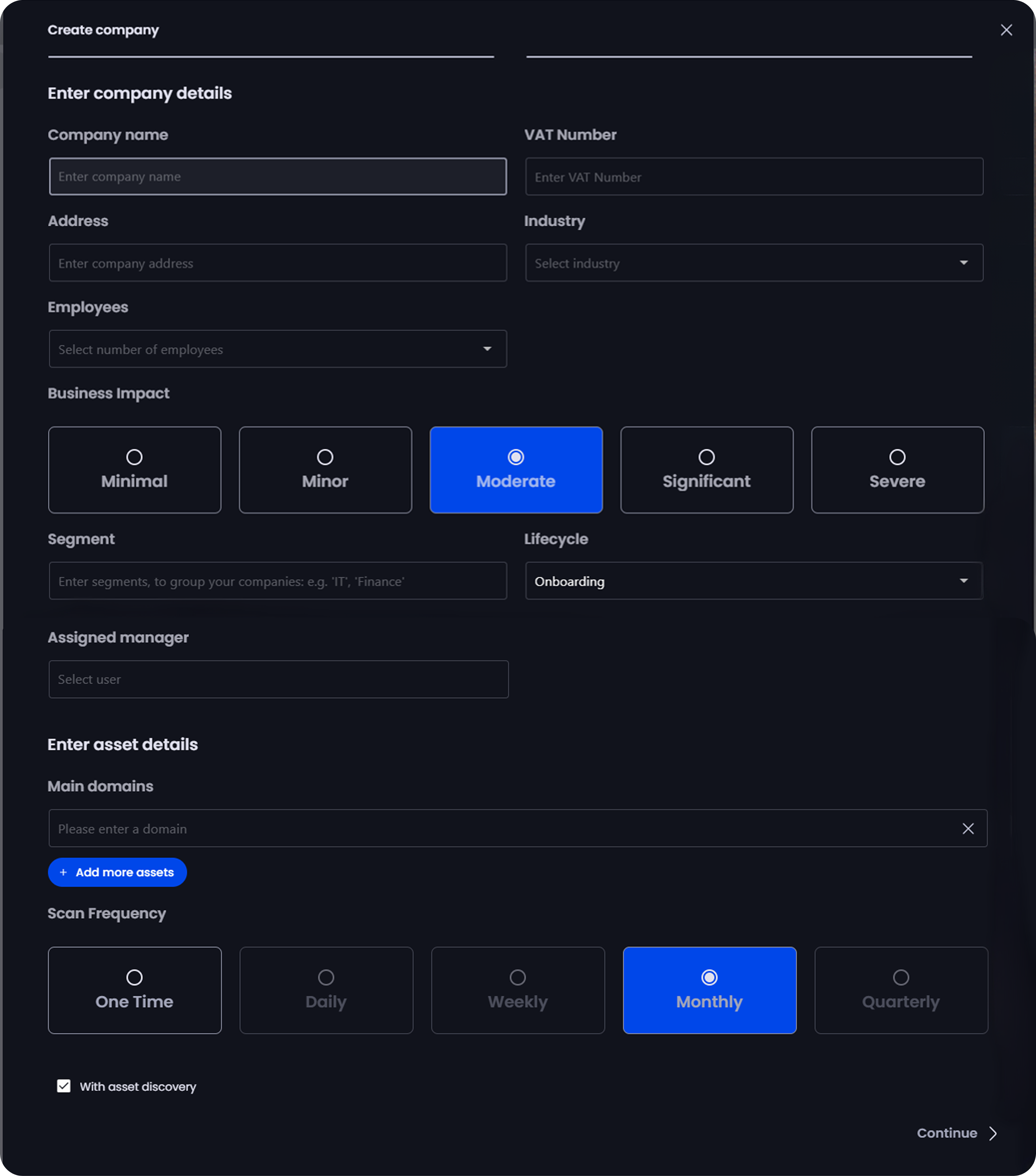
The original form — one-by-one entry, no field hierarchy, no bulk support.
Observing user behavior and gathering input from sales revealed two connected failures: the flow was too slow for scale, and too loose for accuracy.
Onboarding was reframed from a single flow into a system that supports both scale and flexibility. Rather than optimizing form completion, the focus shifted to aligning with how teams manage supplier data at different volumes.
A single flow would force a compromise — either too complex for individual use or too rigid for bulk operations. Two complementary modes allow each to be optimized for its context.
Both modes share the same data model and validation logic, ensuring consistency regardless of how suppliers enter the system.
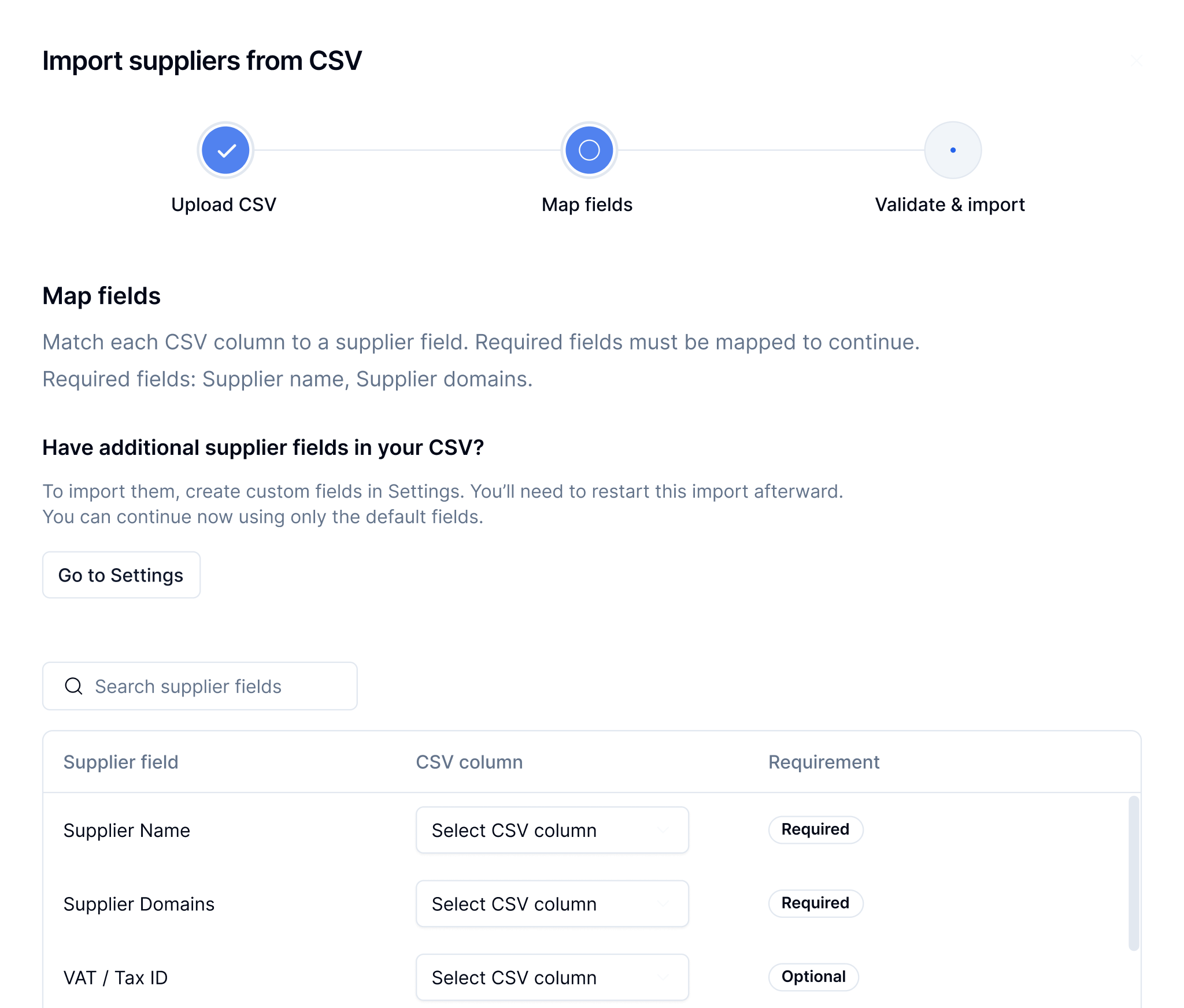
Bulk import is not just about speed — it is controlled onboarding at scale.
To support both high-volume operations and everyday use, onboarding was structured into two complementary entry modes — each optimised for a different context, while sharing the same validation and data logic.
Enterprise teams already managed supplier data in spreadsheets. Importing without structure or validation introduced significant risk.
A guided import flow lets users upload a CSV, map columns to system fields, and validate entries before submission. Errors are surfaced with clear guidance on how to resolve them.
Teams can onboard hundreds of suppliers in a single session while maintaining data quality and consistency.
The original form exposed too many fields at once, slowing users down and increasing errors.
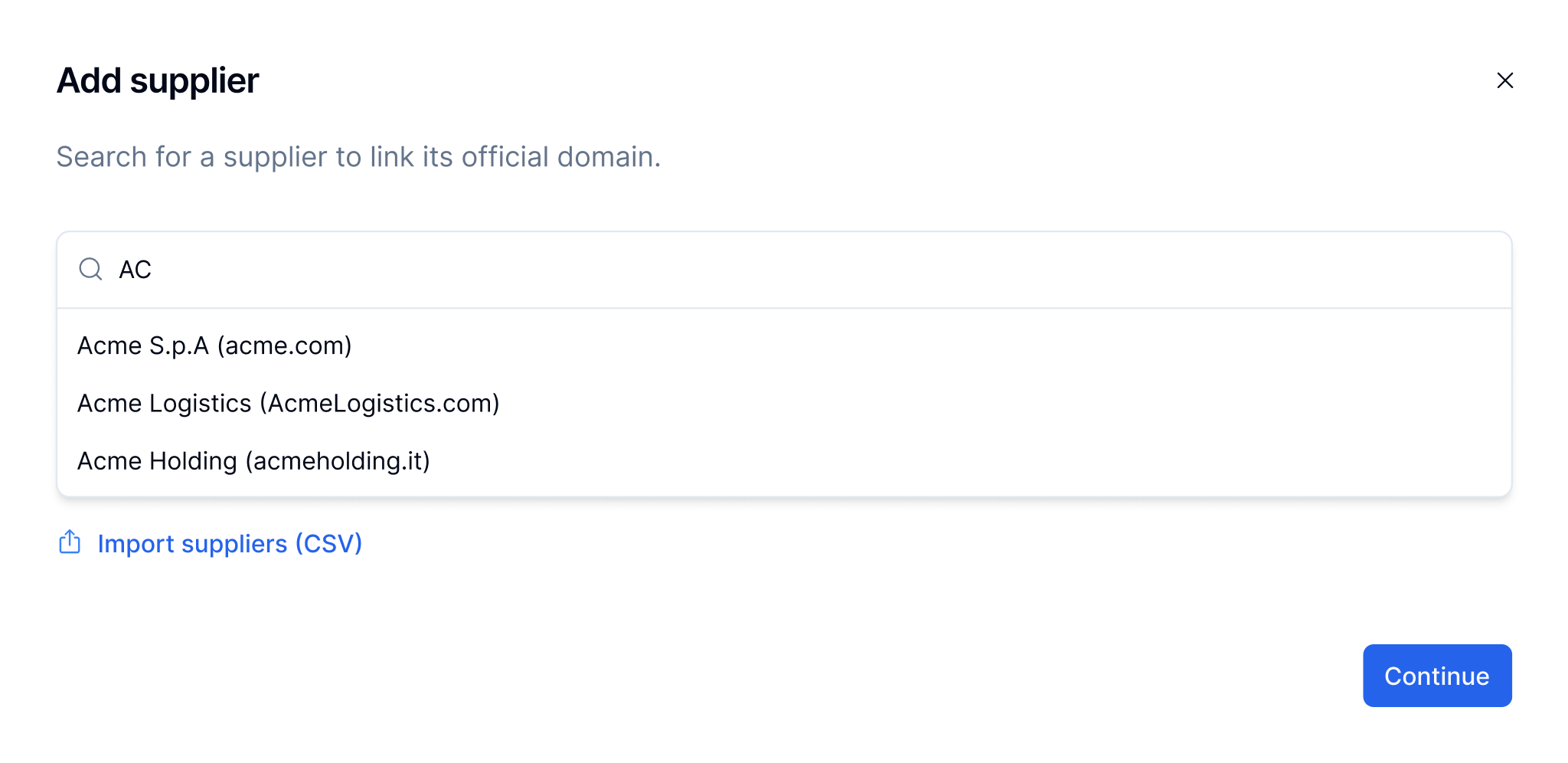
The flow starts with a simple supplier search. If the supplier exists, key data is auto-filled. If not, users continue through a step-by-step flow with prefilled suggestions.
Reduces input effort, speeds up onboarding, and improves accuracy through progressive validation and smart defaults.
Both onboarding modes rely on the same data structure and validation rules. This ensures that regardless of how suppliers are added — individually or in bulk — the data remains consistent and reliable across compliance and audit workflows.
The redesign shifted onboarding from a manual, single-entry process into a scalable system — eliminating spreadsheet workarounds and backend engineering imports entirely. Teams that previously spent entire workdays on data entry can now onboard hundreds of suppliers in a single session, with structured validation ensuring data accuracy across downstream compliance and audit workflows.
First 30 days post-launch · Early signals only.
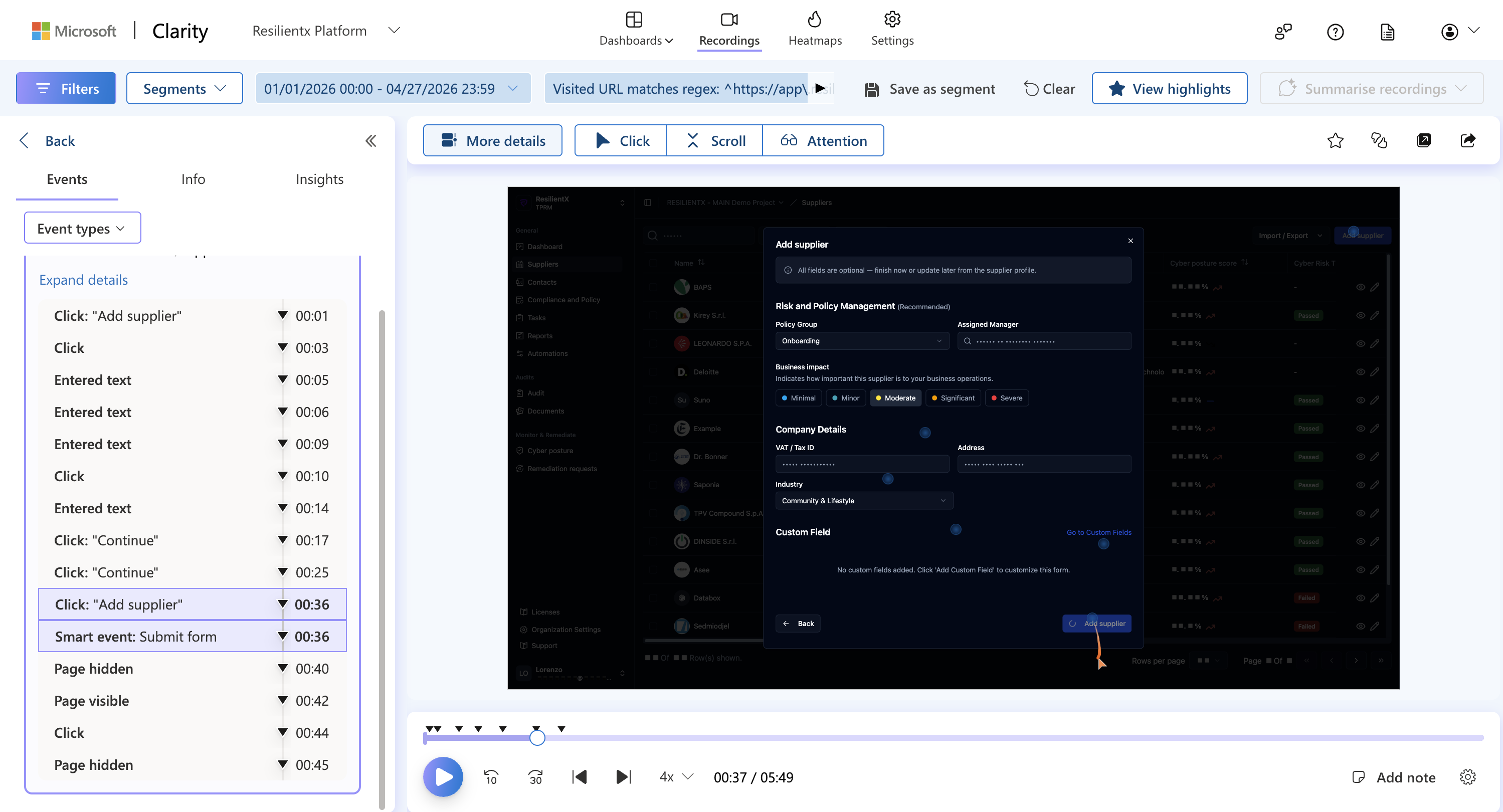
Clarity · session recording · supplier added in 36 sec · Jan–Apr 2026
Rage-click and speed numbers stayed strong. The recordings surfaced two patterns we hadn’t designed for.
For most teams, typing a few suppliers felt faster than preparing a CSV. Bulk complemented single-entry; it didn’t replace it.
My role vs the team’s: I diagnosed both from the recordings. Backend owned Loop 1. Loop 2 wasn’t fixable in code — we agreed it needed a different solution, not another patch.
Findings independently confirmed by the CTO (Clarity recordings) and the CEO (direct customer conversations). AI-assisted data correction is now in the next sprint — cutting manual error resolution where users get stuck.